An Overview of Combine Operators — Part 3
A comprehensive understanding of how Operators work in the Combine framework.
- What is an Operator?
- Types of Operators in Combine
------- Transformation operators
══════════════════════════════════════
║ collect ║ map ║ flat map. ║
══════════════════════════════════════
║ replace nil ║ replace empty ║
══════════════════════════════════════
║ scan ║
══════════════════════════════════════
------- Filter operators
═════════════════════════════════════════
║ filter ║ removeDuplicate ║
═════════════════════════════════════════
║ compact map║ ignore output ║
═════════════════════════════════════════
║ first ║ last ║ drop first ║
═════════════════════════════════════════
║ drop while ║ drop until║ prefix while ║
═════════════════════════════════════════
║ prefix until ║
═════════════════════════════════════════
------- Time manipulation
═════════════════════════════════════════
║ delay ║ collect ║
═════════════════════════════════════════
║ throttle. ║ debounce ║
═════════════════════════════════════════
║ measure ║ timeout ║
═════════════════════════════════════════
------- Combining operators
═════════════════════════════════════════
║ concatenate ║ prepend ║
═════════════════════════════════════════
║ append. ║ switchToLatest ║
═════════════════════════════════════════
║ combineLatest ║ zip ║ merge ║
═════════════════════════════════════════
------- Error handling operators
═════════════════════════════════════════
║ catch ║ replaceError ║
═════════════════════════════════════════
║ setFailureType. ║ mapError ║
═════════════════════════════════════════
║ retry ║ assertNoFailure ║
═════════════════════════════════════════
------- Encoding and decoding operators
═════════════════════════════════════════
║ decode ║ encode ║
═════════════════════════════════════════
------- Debugging operators
═════════════════════════════════════════
║ breakpoint ║ breakpointOnError ║
═════════════════════════════════════════
║ handleEvents. ║ print ║
═════════════════════════════════════════
------- Resource Management operators
═════════════════════════════════════════
║ share ║ multicast ║
═════════════════════════════════════════
║ autoconnect. ║
═════════════════════════════════════════
------- Scheduler and Thread handling operators
═════════════════════════════════════════
║ receive ║ subscribe ║
═════════════════════════════════════════
------- Type erasure operators
═════════════════════════════════════════
║ eraseToAnyPublisher ║
═════════════════════════════════════════
║ eraseToAnySubject. ║ AnySubscriber ║
═════════════════════════════════════════
------- Sequence Operators are mentioned below.- Operator Comparison
═════════════════════════════════════════
║ subscribe(on:) vs receive(on:) ║
═════════════════════════════════════════
║ schedulers vs threads ║
═════════════════════════════════════════
║ replaceError vs catch ║
═════════════════════════════════════════
║ scan vs reduce ║
═════════════════════════════════════════
║ combineLatest vs zip ║
═════════════════════════════════════════
║ delay vs debounce ║
═════════════════════════════════════════
║ multicast vs share ║
═════════════════════════════════════════What is an Operator?
Operators are a set of functions that allow you to transform, filter, combine, and manipulate data streams emitted by publishers.
They are used to building data pipelines by chaining them together to create a series of transformations that can be applied to the data streams emitted by publishers. This allows you to create complex data processing pipelines with relatively few lines of code.

Publishers (and operators) have a receive function that allows them to connect to subscribers.

Transformation operators
These operators allow you to transform the elements emitted by a publisher.
collect
There are a few variants of the collect:
collectByTime: This variant ofcollectgroups emitted values into arrays based on a time interval. It takes two parameters: a time interval and a scheduler. When the specified time interval has passed, the operator emits an array of all the values that were emitted during that interval — it’s a Time manipulation operationcollectByCountbyTimeOrCountit’s a Time manipulation operation

map, tryMap
The map an operator takes a closure that takes one argument, the element emitted by the upstream publisher, and returns a transformed value. The resulting publisher emits the transformed value downstream.

flatMap
transforms each element emitted by an upstream publisher into a new publisher and flattens the resulting publishers into a single sequence of elements.

.flatMap { data in
return Just(data)
.decode(YourType.self, JSONDecoder())
.catch {
return Just(YourType.placeholder)
}
}
flatMap(maxPublishers:)
the flatMap(maxPublishers:) an operator is a variant of the flatMap operator that limits the maximum number of publishers that can be in flight at a time.
Use case: Let’s say you have an array of URLs that represent image files you want to download and display in your app. You want to limit the number of concurrent downloads to 3 to avoid overloading the network. You can use the flatMap(maxPublishers:) operator to achieve this: example
replaceNil
replaces any nil values emitted by a publisher with a provided non-nil value. This operator is useful when you want to ensure that all values emitted by a publisher are non-nil.

If you want to convert an optional type into a concrete type, simply ignoring or collapsing the nil values, you should likely use the compactMap (or tryCompactMap) operator.
replaceEmpty
Replaces an empty stream with the provided element. If the upstream publisher finishes without producing any elements, this publisher emits the provided element, then finishes normally.

Here’s an example of using replaceEmpty
scan, tryScan
the scan an operator is a higher-order function that applies a closure to each element emitted by an upstream publisher, accumulating and returning each intermediate result in a sequence.

Filter Operater
filter the elements of a publisher that satisfy a given predicate.
- Filter, tryFilte.
- rremoveDuplicates.
- compactMap, tryCompactMap.
- first, firstWhere, tryFirstWhere.
- last, lastWhere, tryLastWhere.
- dropWhile, tryDropWhile, dropFirst.
- prefixWhile, tryPrefixWhile.
ignoreOutput
is used to ignore any output from the upstream publisher and only receive its completion event. It returns a Publisher that doesn't emit any values, but only signals a completion event or an error.

prefixUntilOutput
is used to take elements from a publisher until another publisher emits an element. The operator returns a new publisher that emits the elements of the original publisher, but only up to the point where the specified publisher emits an element.

dropUntilOutput
is used to ignore elements from a publisher until another publisher emits its first element.
The operator waits for the first element from a second publisher and then starts emitting elements from the first publisher. Once the second publisher emits its first element, it stops dropping elements and starts forwarding them to its subscribers.
Here’s an example
Time manipulation
manipulate the timing of the events emitted by publishers.
delay
is used to introduce a delay in the emission of values from a publisher. It can be useful in cases where you need to introduce a delay to synchronize or control the rate of data flow.
Delays delivery of all output to the downstream receiver by a specified amount of time on a particular scheduler.

timeout
is used to emit an error if a publisher does not emit any values within a specified time interval.
The timeout an operator can be used to handle scenarios where a publisher might become unresponsive or take too long to emit values. It can also enforce a timeout for a specific operation or task.
The timeout operator has two variations:
timeout(_:scheduler:options:). timeout(_:scheduler:customError:options:).
The first variation takes a time interval and a scheduler and emits an TimeoutError if the publisher does not emit any values within that time interval. The options a parameter can be used to customize the behavior of the operator.
The second variation takes a time interval, a scheduler, a custom error, and an options parameter. This variation allows you to specify a custom error to emit if the timeout occurs, instead of the default TimeoutError.

collectByTime, byTimeOrCount
It is introduced above in the transforming section.
collectByTime example
byTimeOrCount example
debounce
an operator that delays the delivery of elements from the upstream publisher until a specified amount of time has passed without any new elements being emitted. This can be useful when dealing with rapidly changing values, such as user input or sensor data, where you want to avoid processing unnecessary intermediate values and only process the latest value after a certain period of inactivity.

The debounce an operator takes a time interval parameter and emits the latest element from the upstream publisher only after the specified time interval has elapsed without any new elements being emitted. If a new element is emitted during the debounce period, the timer resets, and the debounce period starts over.
Here’s an example of using the debounce operator to handle user input from a text field
throttle
is used to limit the rate at which values are emitted by a publisher. It returns a publisher that emits only the first value from the upstream publisher within a specified time window and then ignores subsequent values until the time window expires.
func throttle<Scheduler: SchedulerType>(
for dueTime: Scheduler.SchedulerTimeType.Stride,
scheduler: Scheduler,
latest: Bool
) -> Publishers.Throttle<Self, Scheduler>The for a parameter is the time window for the throttle, the scheduler a parameter is a scheduler used to manage the throttle and the latest the parameter determines whether the publisher should emit the latest value that was received during the throttle period or the first value that was received during the throttle period.

true
falsemeasureInterval
is used to measure the time interval between consecutive emissions of values from a publisher. It returns a publisher that emits a tuple with two values for each value emitted by the upstream publisher: the first value is the emitted value, and the second value is the time interval between the emission of the previous value and the emission of the current value.

Combining operators
These operators allow you to combine multiple streams of data into a single stream.
- append
Concatenate
is used to concatenate the output of multiple publishers into a single stream of output.

prepend
used to add one or more elements to the beginning of a publisher’s output. The operator returns a new publisher that emits the specified elements, followed by the elements of the original publisher.
it has three variant prepend(output..) , prepend(sequence..) , prepend(publisher..)

switchToLatest
is used to subscribe to the latest publisher that is emitted by a publisher of publishers. It returns a new publisher that emits values from the most recent publisher and ignores any values emitted by previous publishers.
Here’s an example that demonstrates how to use the switchToLatest operator to subscribe to the latest publisher that is emitted by a publisher of publishers
another example of using the switchToLatest operator to download the contents of a URL and display them in the console


merge
is used to combine the output of multiple publishers into a single stream of values. The operator returns a new publisher that emits the values from all input publishers, in the order in which they are received.

combineLatest
is used to combine the latest elements from multiple publishers into a new publisher that emits a tuple of the combined values. The operator returns a new publisher that emits a new tuple of values whenever any of the input publishers emits a new value.

If any of the upstream publishers finish normally (that is, they send a .finished completion), the combineLatest an operator will continue operating and processing any messages from any of the other publishers that have additional data to send.
Zip
is used to combine the latest values from multiple publishers into tuples. This operator takes multiple publishers as input and returns a new publisher that emits tuples of the latest values from each input publisher whenever any of them emit a new value.

The zip an operator is useful when you want to combine the latest values from different publishers. For example, if you have two publishers that emit the current temperature and humidity, you can use zip them to create a new publisher that emits a tuple of the current temperature and humidity whenever either of them changes.
Error Handling
These operators allow you to handle errors that occur in a data pipeline.
catch, tryCatch
an operator that allows you to recover from errors that may occur in a publisher by replacing the error with another publisher or a default value.

Let’s say we have a publisher that emits an error at some point, and we want to handle that error and continue with a fallback publisher. We can use the catch operator to do this example
replaceError
an operator in the Combine framework that replaces any error produced by a publisher with a provided value, and then completes normally. This operator can be useful when you want to handle errors in a specific way, for example by replacing them with a default value or a custom error message.
The replaceError the operator has two variants, one that replaces errors with a single provided value, and one that replaces errors with the values emitted by another publisher. Here's an example of using the first variant to replace errors with a default value
Here’s an example of using the second variant replaceError to replace errors with values emitted by another publisher
setFailureType
The setFailureType operator in Combine is used to change the type of error that a publisher can emit. It allows you to convert an error of one type to another error type, or even to a non-error value so that downstream subscribers can handle the new error type or value instead of the original one.

Here’s an example that demonstrates how to use the setFailureType operator to convert an error type to another error type
mapError
operator in Combine is used to transform errors from one type to another. It returns a new publisher that emits the same values as the upstream publisher, but with a transformed error type.
The mapError an operator takes a closure that transforms the error type of the upstream publisher and returns a new publisher with the transformed error type.
Here’s an example that demonstrates how to use the mapError operator to transform errors from one type to another
retry
an operator that allows you to resubscribe to a publisher when it fails, in order to attempt to recover from the failure and continue receiving events.
The retry an operator takes a single parameter: the maximum number of times to attempt the re-subscription. If the publisher fails, the retry operator will attempt to resubscribe up to the specified number of times before passing on the error to the downstream subscriber.

In summary, the retry operator is a useful tool for recovering from errors in a publisher and attempting to continue receiving events. It can be useful when working with network requests or other asynchronous operations that may occasionally fail.
assertNoFailure
an operator that ensures that a publisher emits no errors. If an error is emitted by the upstream publisher, it will cause a fatal error in the application.

Here’s an example that demonstrates the assertNoFailure operator
Encoding and decoding
used to transform data between different formats.
encode
is used to encode elements of a stream into a specific format using an instance of a type that conforms to the Encoder protocol.
The encode(encoder:)-[Output] an operator can be used to convert elements of a stream into a different representation or format, such as JSON or binary data. This is useful when communicating with web services or other systems that require data in a specific format.
Here’s an example of using the encode(encoder:)-[Output] operator to encode a stream of custom objects into a JSON representation:
decode
is used to decode elements of a stream from a specific format, such as JSON or binary data, into instances of a specified type that conforms to the Decodable protocol.
Here’s an example of using the decode(type:decoder:)-[Publishers.Output] operator to decode a stream of JSON data into instances of a custom User struct
Debugging
these operators can help you better understand how your publishers and subscribers are working.
breakpoint
used to help debug a stream of values emitted by a Publisher.
When you insert breakpoint into a chain of operators, it will pause the subscription and allow you to inspect the values emitted by the upstream Publisher before continuing. You can also specify a closure to be executed when the breakpoint is hit, which can be useful for logging or other debugging purposes.

The operator takes 3 optional closures as parameters, used to trigger when to raise a SIGTRAP signal:
receiveSubscriptionreceiveOutputreceiveCompletion
Here’s an example of how you might use breakpoint to inspect the values emitted by a Publisher
breakpointOnError
similar to the breakpoint operator in Combine, but it only pauses the pipeline when an error is encountered. This can be useful for debugging errors in Combine pipelines.

handleEvents
used to observe different lifecycle events of a publisher without affecting the values of the original publisher. It allows you to observe events such as subscription, receiving values, completion, and cancellation.

The operator takes four closures that correspond to different events:
receiveSubscription: Called when the downstream subscriber first connects to the publisher.receiveOutput: Called when the publisher sends a value to its subscriber.receiveCompletion: Called when the publisher has finished publishing values, either normally or with an error.receiveCancel: Called when the subscriber cancels the subscription to the publisher.
The handleEvents operator returns a publisher that emits the same values as the upstream publisher, but with the specified side effects for each event.
Here’s an example usage of the handleEvents operator
used for debugging purposes. It allows you to print out the events and values emitted by a publisher in the console, so you can see what’s happening at various stages of your pipeline.

Resource Management
used to manage the lifecycle of resources.
share
is used to share a single subscription to a publisher among multiple subscribers. When a publisher has multiple subscribers, each subscriber receives its own stream of elements. However, this can result in the publisher being subscribed multiple times, which can lead to duplicate work and unexpected behavior.

The share() operator helps to avoid this problem by sharing a single subscription to the publisher among all subscribers. This means that when the first subscriber connects to the publisher, the publisher starts publishing elements, and subsequent subscribers receive the same stream of elements without the publisher being subscribed multiple times.
Here’s an example of using the share()-[Publishers.Output] operator to share a single subscription to a publisher among multiple subscribers
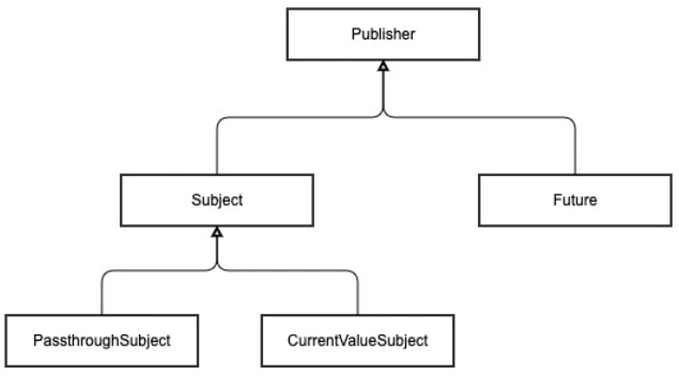
multicast
is used to multicast (or share) a single upstream subscription to multiple downstream subscribers. It allows you to create a single subscription to the upstream publisher, and then share the received values among multiple subscribers.

The multicast(_:) operator takes a Subject as a parameter, which is used to multicast the upstream publisher's values to its subscribers. You can use any Subject type, such as PassthroughSubject, CurrentValueSubject, or a custom Subject that you define.
autoconnect
is automatically connected to the upstream publisher when there is at least one downstream subscriber, and automatically disconnects from the upstream publisher when there are no more subscribers.
By default, publishers in Combine are cold, meaning that they don’t emit events until a subscriber starts listening. When a subscriber disconnects, the publisher stops emitting events. If another subscriber subscribes after the first one has disconnected, the publisher will start emitting events again from the beginning.
The autoconnect() operator makes a cold publisher into a hot publisher that continues emitting events regardless of whether there are subscribers or not. When the first subscriber subscribes, the autoconnect() operator automatically connects to the upstream publisher and starts emitting events. When the last subscriber unsubscribes, the autoconnect() operator automatically disconnects from the upstream publisher.
Scheduler and Thread handling operators
Schedulers are objects in the Combine framework that define the execution context for publishers and subscribers. They specify which queue or thread a publisher or subscriber should execute on. Schedulers are important for controlling the timing and concurrency of events in the Combine framework.
Schedulers can be thought of as a kind of “traffic controller” for data streams. They determine when and where events are processed and can help ensure that events are processed in a thread-safe and efficient manner. By using schedulers, developers can control the timing and concurrency of events in their reactive applications, ensuring that they behave predictably and efficiently.
How do Schedulers Work in Combine?
Schedulers in Combine are represented by the Scheduler protocol. There are several built-in implementations of the Scheduler protocol, including DispatchQueue, RunLoop, and OperationQueue. These implementations provide different execution contexts for publishers and subscribers.
Schedulers can also be used with operators in the Combine framework to specify the execution context for each step in a data processing pipeline. For example, you can use the subscribe(on:) operator to specify the scheduler on which a publisher should emit values, and the receive(on:) operator to specify the scheduler on which a subscriber should receive values.
receive
used in Combine to specify which scheduler should be used for receiving and handling events emitted by a publisher. It is commonly used when a publisher emits events on a background queue and we need to handle those events on the main queue to perform UI updates or any other task that requires main thread access.
it takes a single required parameter (on:) which accepts a scheduler, and an optional parameter (optional:) which can accept SchedulerOptions. A scheduler is a protocol in Combine, with the conforming types that are commonly used of RunLoop, DispatchQueue, and OperationQueue.
The operator takes a Scheduler parameter, which specifies the scheduler on which the receiving and handling should occur. For example, to receive and handle events on the main thread, we can pass the Runloop.main scheduler to the .receive(on:) operator as follows:
publisher
.receive(on: RunLoop.main)
.sink { value in
// Handle received events on the main thread
}The .receive(on:) an operator does not affect where the publisher emits events from, it only specifies where the events are received and handled. It can be used in combination with other operators such as map, filter, flatMap, etc. to customize the event handling pipeline.
subscribe(on:)
is an operator that allows you to specify the scheduler on which to receive elements from a publisher.
Publishers may produce values on a particular scheduler, and by default, subscribers receive these values on the same scheduler. However, you may want to receive values on a different scheduler. This is where the subscribe(on:) operator comes in.
Note that subscribe(on:) does not affect the scheduler on which the subscription occurs. It only affects the scheduler on which values are produced. If you want to specify a scheduler for the subscription itself, you can use the receive(on:) operator.
Common Use Cases for Schedulers in Combine
There are several common use cases for working with schedulers in the Combine framework:
- Controlling Concurrency: Schedulers can be used to control the concurrency of data processing operations in reactive applications. For example, you can use schedulers to ensure that expensive or time-consuming operations are executed on a background thread, while UI-related operations are executed on the main thread.
- Delaying or Throttling Events: Schedulers can be used to delay or throttle the emission of events or values from a publisher. For example, you can use the
debounceoperator to delay the emission of events until a certain amount of time has elapsed, or thethrottleoperator to limit the rate at which events are emitted. - Testing and Debugging: Schedulers can be used to test and debug reactive applications. For example, you can use the
TestSchedulerimplementation of theSchedulerprotocol to simulate the passage of time and control the execution context of data processing operations in unit tests.
In addition, the following operators take the scheduler and it’s options as parameters:
- • debounce(for:scheduler:options:)
- • delay(for:tolerance:scheduler:options:)
- • measureInterval(using:options:)
- • throttle(for:scheduler:latest:)
- • timeout(_:scheduler:options:customError:)
Type erasure operators
used to erase the type of a publisher or subscriber.
eraseToAnyPublisher
is an operator in Combine that converts any publisher into an AnyPublisher. This can be useful in situations where the publisher's type is not known or does not matter, such as when passing publishers between functions or APIs.
When you use eraseToAnyPublisher(), you can no longer access the original publisher's methods or properties that are not defined in the Publisher protocol. Instead, you can only use the methods and properties defined in the Publisher protocol.
Note that eraseToAnyPublisher() is often used at the end of a chain of publishers to ensure that the final publisher has a consistent type, regardless of the specific publishers that were used earlier in the chain.
eraseToAnySubject
It converts the upstream publisher into an AnySubject, which can be used to send values and errors to its subscribers. This operator can be used to hide the underlying publisher type, which can be useful in cases where the publisher type is complex or not important to the downstream subscribers.
AnySubscriber
Use an AnySubscriber to wrap an existing subscriber whose details you don’t want to expose. You can also use AnySubscriber it to create a custom subscriber by providing closures for the methods defined in Subscriber, rather than implementing Subscriber directly.
Here’s an example of using AnySubscriber
Sequence Operators
allow you to manipulate and transform sequences of values.
- max, tryMax
- min, tryMin
- count
- allSatisfy, tryAllSatisfy
- contains, containsWhere, tryContainsWhere
- first
- last
- reduce
Comparison:
subscribe(on:) vs receive(on:)
subscribe(on:) and receive(on:) are both operators that control the execution context for upstream and downstream operators. However, they do so in slightly different ways:
subscribe(on:)affects the execution context for the upstream publisher. It specifies which scheduler the upstream publisher should use to produce values and send them downstream. This can be useful for avoiding concurrency issues when dealing with publishers that generate events on different threads or queues than the downstream operator.receive(on:)affects the execution context for the downstream subscriber. It specifies which scheduler the downstream subscriber should use to receive values and handle events from upstream. This can be useful for ensuring that downstream processing happens on a specific thread or queue, especially if that processing involves UI updates or other tasks that need to be performed on the main thread.

- The publisher receives the subscriber and creates a Subscription.
- Subscriber receives the subscription and requests values from the publisher (dotted lines).
- The publisher starts work (via the Subscription).
- The publisher emits values (via the Subscription).
- Operators transform values.
- Subscriber receives the final values.
In summary, subscribe(on:) controls the execution context for the upstream publisher, while receive(on:) controlling the execution context for the downstream subscriber.
Schedulers and Threads
In the Combine framework in iOS, schedulers and threads are both important concepts for managing concurrency and scheduling work.
Schedulers are responsible for managing the execution of Combine operators and publishers. They determine the thread on which a particular operator or publisher will execute, as well as the timing and order of execution. The Combine framework provides several built-in schedulers, such as DispatchQueue, OperationQueue, and RunLoop, which you can use to control the timing and execution of your Combine operators.
Threads, on the other hand, are the fundamental units of execution in a program. They represent a single path of execution in a program’s code and can execute independently of other threads. In the context of the Combine framework, threads can be used to execute work concurrently, allowing for greater performance and responsiveness in your app. You can use the DispatchQueue API to create custom threads or use the built-in global concurrent queues to execute work concurrently.

What you see in the figure above:
- A user action (button press) occurs on the main (UI) thread.
- It triggers some work to process on a background scheduler.
- Final data to display is delivered to subscribers on the main thread, so subscribers can update the app‘s UI.
- You can see how the notion of scheduler is deeply rooted in the notions of foreground/background execution. Moreover, depending on the implementation you pick, work can be serialized or parallelized.
Therefore, to fully understand schedulers, you need to look at which classes conform to the Scheduler protocol.
In summary, schedulers and threads both play important roles in managing concurrency and scheduling work in the Combine framework. Schedulers provide a high-level abstraction for managing the execution of Combine operators, while threads provide a lower-level abstraction for managing concurrent execution. Together, they enable you to create efficient, responsive, and scalable iOS apps that can handle complex asynchronous operations.
replaceError vs catch
Both replaceError and catch are Combine operators that deal with error handling, but they have different behavior.
replaceError operator replaces any errors produced by a publisher with a provided value, and then completes normally. This can be useful when you want to handle errors in a specific way, such as replacing them with a default value or a custom error message. However, replaceError does not allow you to recover from an error and continue the subscription.
catch operator, on the other hand, allows you to recover from an error and continue the subscription with another publisher. It does this by subscribing to a "catching" publisher when an error is received, and then continuing the subscription with the values emitted by the catching publisher. This can be useful when you want to recover from an error and continue the subscription with a backup publisher, or when you want to handle errors in a more complex way.
Here’s an example to illustrate the difference between replaceError and catch
In summary, replaceError is useful when you want to handle errors in a specific way and replace them with a provided value, while catch is useful when you want to recover from an error and continue the subscription with another publisher.
scan vs reduce
The reduce and scan operators in Combine are similar in that they both combine all the values emitted by a publisher into a single value. However, there are some differences between the two:
reducereturns a single value as the output of the operator, whilescanreturns a sequence of values as each value is accumulated.reducetakes an initial value as the first accumulated value, whilescanuses the first emitted value from the publisher as the initial accumulated value.- The closure provided to
reducecombines the current accumulated value with the next element emitted by the upstream publisher and returns a new accumulated value. The closure provided toscanperforms the same operation, but also returns the intermediate accumulated values.

combineLatest vs zip
combineLatest emits a new value whenever any of its input publishers emit a new value. When a new value is emitted, combineLatest takes the latest value from each of its input publishers and combines them into a tuple. The resulting publisher emits these tuples.
In contrast, zip waits until all of its input publishers have emitted a new value before emitting a new value itself. When all of its input publishers have emitted a new value, zip takes the latest value from each publisher and combines them into a tuple. The resulting publisher emits these tuples.
Here’s an example that demonstrates the difference between combineLatest and zip
delay vs debounce
While both the delay and debounce operators in Combine can introduce a delay in the emission of values from a publisher, they have different use cases.
The delay operator delays the emission of all values by a specified amount of time. This can be useful in cases where you want to introduce a fixed delay in the emission of values, such as to simulate network latency or to control the rate of data flow.
On the other hand, the debounce operator only emits a value from the publisher if a certain amount of time has passed without any new values being emitted. This can be useful in cases where you want to filter out rapid changes in a value, such as user input events, and only emit the latest value after a certain amount of time has passed without any new changes.
For example, if you have a search bar that sends search queries to a server every time the user types a new character, you can use the debounce operator to delay the sending of the search query until the user has stopped typing for a certain amount of time, such as 500 milliseconds, to avoid sending too many unnecessary queries.
multicast vs share
Both multicast and share are operators that can be used to share a single subscription to a Publisher among multiple subscribers. However, they differ in some key ways.
multicast is an operator that allows you to share a single subscription to a Publisher among multiple subscribers, while also specifying a Subject that will be used to multicast the values emitted by the Publisher to its subscribers. multicast is a multi-step operation that involves creating a Subject, calling the multicast an operator on the original Publisher and passing in the Subject, and then calling the connect method on the result of the multicast operator to start the subscription.
share, on the other hand, is a shorthand way of achieving the same result as multicast, but with less setup. It uses a special type of Subject called a PublishSubject under the hood, which automatically creates and manages the multicast subscription for you. When you call share on a Publisher, it creates a new PublishSubject, calls multicast on the original Publisher, passing in the PublishSubject, and then calls connect on the result of multicast automatically.
In summary, multicast is a more flexible operator that allows you to choose the type of Subject used for multicasting and provides you with more control over the setup process, while share is a more convenient shorthand that uses a PublishSubject under the hood to automatically manage the multicasting subscription for you.
A multicast publisher does not cache or maintain the history of a value. If a multicast publisher is already making a request and another subscriber is added after the data has been returned to previously connected subscribers, new subscribers may only get a completion. For this reason, multicast returns a connectable publisher.
Ref:
Combine: Asynchronous Programming with Swift third edition.
Using Combine: Joseph Heck
Combine Mastery in SwiftUI by Big Mountain Studio
If you have any questions or comments on this tutorial, do not hesitate to contact me: Linkedin, Twitter, or Email: alsofiahmad@yahoo.com.
Thanks for reading!😀